This post is the continuation of Xvfb and Firefox headless screenshot generator where I explained how Xvfb and Firefox can be used to get a screenshot of any web resource supported by firefox.
The next challenge I had, involved the creation of an automated process that could be called from the web or from a cron job, this process job would take a list of sites that need to be captured, and it will save its shots with their respective thumbnail somewhere, also this same process had to communicate somehow with the front end, to inform the user about the status.
So I’ve planned the architecture for this solution in a modular way
- A daemon checking if new jobs were sent.
- The main process that takes some parameters including the site list and save the generated screenshots somewhere.
- A logger facility to communicate with an external process.
- A web application to take the site list and show the results.
This is the architecture diagram:
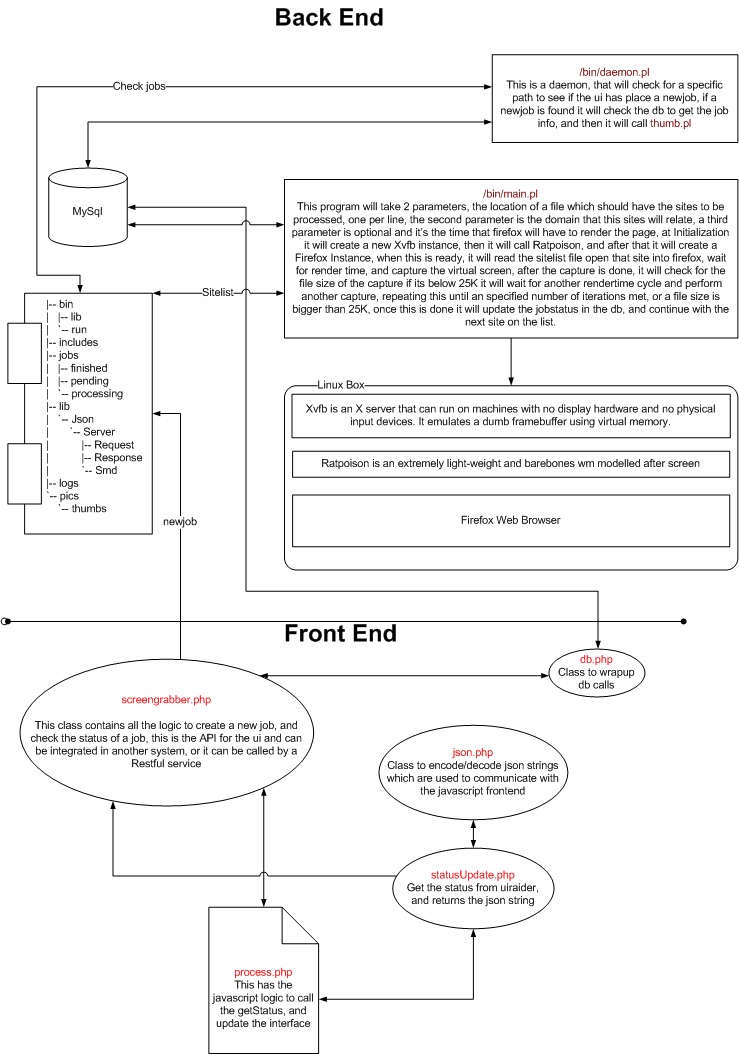
From the above modules, I will describe briefly the Main process, this main process started as a simple bash script but this wasn’t sufficient for scalability and security standpoints, so I’ve decided to make it in perl.
The current version has changed a lot, but I will describe the main aspects of this script:
The following CPAN extensions were used in this module:
This process receives the following arguments:
- The path to a file where the list of urls are, the filename represents the job name and this file must contain 1 url per line (Required)
- The number of seconds that firefox will have to render each url (Optional)
After the main process is called, either by a daemon or by a cron job, it will connect to a database and search the job based on the received parameter, this job needs to be inserted with an API I did in php, this API is called from the frontend and the cron jobs as well and it serves as a glue point between everything.
After the update is done, I prepare the environment for Xvfb and spawn a new Virtual Screen with its corresponding firefox instance:
This is the code used:
sub initialize {
logThis("======= Process Starting ==========", 1);
my $numArgs = $#ARGV + 1;
if ($numArgs < 1) {
logThis("Bad number of parameters", 1);
die "Bad Number of params \n";
}
chomp($siteList = $ARGV[0]);
if ($numArgs > 2) {
chomp($renderTime = $ARGV[2]);
}
($jobName, my $dirName, my $fileExtension) = fileparse($siteList, ('\.processing') );
logThis("Parameters received \nSiteList: $siteList\nRelated Domain:$relatedDomain\nRender Time: $renderTime",1);
logThis("Initializing Db",3);
$dsn = "DBIdatabase=$db{'name'};host=$db{'host'};port=$db{'port'}";
$dbh = DBI->connect($dsn, $db{'user'}, $db{'pass'}) or die('failed to connect');
my $jobRow = my $domain = $dbh->selectrow_hashref("SELECT idJobs FROM jobs WHERE jobName = ?",undef,$jobName);
$jobId = $jobRow->{'idJobs'};
my $result = $dbh->do("UPDATE jobs SET dateStarted = CURRENT_TIMESTAMP WHERE jobName = ?",undef,$jobName);
logThis("Conected to Db $db{'name'}",1);
jobUpdate(2, "Starting capture process...");
$ENV{'DISPLAY'} =':1';
logThis("Starting virtual screen...",3);
$pid{'xvfb'} = spawn $xvfbBin, ':1', '-screen', '0', '1024x768x24' or die "Xvfb failed to start $!";
logThis("Xvfb Pid: $pid{'xvfb'} ",3);
$pid{'ratpoison'} = spawn 'ratpoison' or die "spawn ratpoison failed";
logThis("Ratpoison Pid: $pid{'ratpoison'} ",3);
sleep(1);
$pid{'firefox'} = spawn $ffBin, '-width 1024', '-height 768' or die "spawn $!";
logThis("Firefox Process Id: $pid{'firefox'}",1);
sleep(5);
logThis("---Initialize sub end here---",4);
return 1;
}After the initialization I proceed to read the list of files to start capturing each one, this is the code that does exactly that:
while (<file>) {
my $site = $_;
chop($site);
##
# Validate that the line starts with http or https
##
if ($site =~ m!\b(https?)://!i) {
logThis("Processing: $site",4);
captureSite($site, $relatedDomainId);
logThis("Sites Processed" . $stats{'processed'} ."=". $stats{'succesfull'} ."+". $stats{'failed'} ."+". $stats{'unrendered'} ."entre ".$stats{'siteCount'},1);
$stats{'percentage'} = ($stats{'processed'}/$stats{'siteCount'})*100;
updateStatus('stats', \%stats);
}
}</file>And the captureSite sub is where the magic is, here it is:
sub captureSite {
my $site = shift;
my $result;
my $imgName;
my $imageStatus = '';
my $fileNameExit = 0;
my $imgCounter = 0;
my $imgFullName;
my $thumbFile;
updateStatus('status', "Processing $site");
jobUpdate(2, "Processing $site");
logThis("Starting to capture: $site",2);
##
# Check the domain for valid parts
##
my @domainParts = $site =~ m/\b((?#protocol)https?|ftp):\/\/((?#domain)[-A-Z0-9.]+)((?#file)\/[-A-Z0-9+&@#\/%=~_|!:,.;]*)?((?#parameters)\?[-A-Z0-9+&@#\/%=~_|!:,.;]*)?/ig;
if ($domainParts[0] && $domainParts[1]) {
if ($openedTabs > $maximumTabs) {
logThis("Maximum Number of Opened Tabs Reached Killing Firefox pid $pid{'firefox'}",3);
kill 0, $pid{'firefox'};
sleep(2);
$pid{'firefox'} = spawn $ffBin, '-width 1024', '-height 768' or die "spawn $!";
logThis("New Firefox Process Id: $pid{'firefox'}",1);
sleep(3);
$openedTabs = 1;
}
#because ff is tabless the old page doesn't disappear until
#all content is loaded, so I should remove content first.
$cmd = $ffBin . ' -remote "openUrl(http://localhost/blank.html)"';
my $res = `$cmd`;
sleep(1);
$cmd = $ffBin . ' -remote "openUrl('.$site.')"';
logThis("Opening $site",1);
logThis($cmd, 3);
$res = `$cmd`;
$openedTabs++;
logThis("Waiting $renderTime seconds to allow page rendering",3);
sleep($renderTime);
##
# We remove harmfull charachters
# maybe an md5sum would be better, because
# we would always have the same number of chars
##
$imgName = $site;
$imgName =~ s!\b(https?)://|(www\.)!!g; #removes http://www
$imgName =~ s!\/|\#|\?$!!g; #removes \ # ? from the end
$imgName =~ s![^0-9^A-Z^a-z^_^.]!_!g;
#cut excessive large filenames
if (length($imgName) > $maxFileNameLength) {
$imgName = substr $imgName, 0, $maxFileNameLength;
}
my $baseImgName = $imgName;
while (!$fileNameExit) {
$imgFullName = $saveDir . $imgName . $saveFormat;
$thumbFile = $thumbsDir . 'thumb_' . $imgName . $saveFormat;
logThis($imgFullName,1);
logThis("Cecking if image already exists",1);
if (-e $imgFullName) {
$imgCounter++;
$imgName = $baseImgName . '_' . $imgCounter;
} else {
$fileNameExit = 1;
}
}
#creating the screenshot
$cmd = 'import -window root ' . $imgFullName;
logThis("Command: " .$cmd, 3);
$res = `$cmd`;
if (-e $imgFullName) {
logThis("The image $imgFullName was created succesfully",1);
$imageStatus = 'success';
my $fileSize = -s $imgFullName;
logThis("File Size for image created: $fileSize",1);
# Check the filesize, if its to low wait give more time to render the page
if ($fileSize < = $minFileSize) {
logThis("File is too small, I think the page has not finished rendering, giving it more time...",2);
my $exit = 0;
my $try = 0;
while (!$exit) {
logThis("Giving the page $renderTime more seconds to render...",2);
updateStatus('status', "Giving $site more time to render...");
sleep($renderTime);
logThis("Command: " .$cmd, 3);
$res = `$cmd`;
$fileSize = -s $imgFullName;
logThis("File Size for image created: $fileSize",1);
if ($fileSize > $minFileSize) {
$exit = 1;
$imageStatus = 'success';
} else {
$try++;
}
if ($try > 3 ) {
$exit = 1;
$imageStatus = 'failed';
}
}
}
logThis("Croping image...",1);
$cmd = "convert $imgFullName -crop '1024x768+0+24' $imgFullName";
$res = `$cmd`;
logThis("Creating Thumbnail in $thumbFile",1);
$cmd = "convert $imgFullName -resize '170x128' $thumbFile";
$res = `$cmd`;
my %image = (
site => $site,
image => $imgFullName,
thumb => $thumbFile,
status => $imageStatus,
);
push(@images, \%image);
insertImage($site, $imgFullName, $thumbFile, $relatedDomainId, $imageStatus);
if ($imageStatus eq 'success') {
$stats{'succesfull'}++;
} else {
$stats{'failed'}++;
}
} else {
logThis("Fail creating the image",1);
$stats{'unrendered'}++;
}
} else {
$stats{'unrendered'}++;
}
$stats{'processed'}++;
jobUpdate(2, "Finished processing $site");
}As you can see I’m updating the job status in the jobUpdate sub, also there are other subs to take care of inserting the screenshot info in the db.
When this program ends, it updates the db to let the inform the daemon that is ready to take more jobs.
In the next post I will be providing info on how the frontend works, and what the final results of this implementation ended.